VLM Agents Generate Their Own Memories:
Distilling Experience into Embodied Programs of Thought
NeurIPS 2024 Spotlight Paper
 Paper
Paper
 Code
Code
Abstract
Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot learning but require high-quality demonstrations. We propose In-Context Abstraction Learning (ICAL), enabling VLM agents to transform suboptimal trajectories into high-quality training data through self-reflection and human feedback. Given imperfect task demonstrations, a VLM abstracts trajectories into generalized strategies and action annotations by correcting inefficiencies and annotating cognitive abstractions: causal relationships, object state changes, temporal subgoals, and task-relevant visual elements. These annotations are iteratively refined through human feedback during execution in similar environments. The resulting examples significantly improve decision-making when used for retrieval-augmented generation or fine-tuning. As the agent's example library grows, it becomes more efficient at abstracting new examples, requiring less human feedback and fewer environment interactions. ICAL achieves state-of-the-art results across multiple benchmarks. In TEACh dialogue-based instruction following, combining fine-tuning and retrieval on ICAL examples outperforms raw human demonstrations and expert examples by 17.5\% in goal-condition success. In VisualWebArena, retrieval-augmented GPT-4V with ICAL improves task success 1.6x, while fine-tuned Qwen2-VL achieves 2.8x improvement over the base model. In Ego4D action forecasting, we surpass few-shot GPT-4V and remain competitive with supervised models. Our approach scales 2x better than raw demonstrations and significantly reduces manual prompt engineering requirements.

ICAL Method
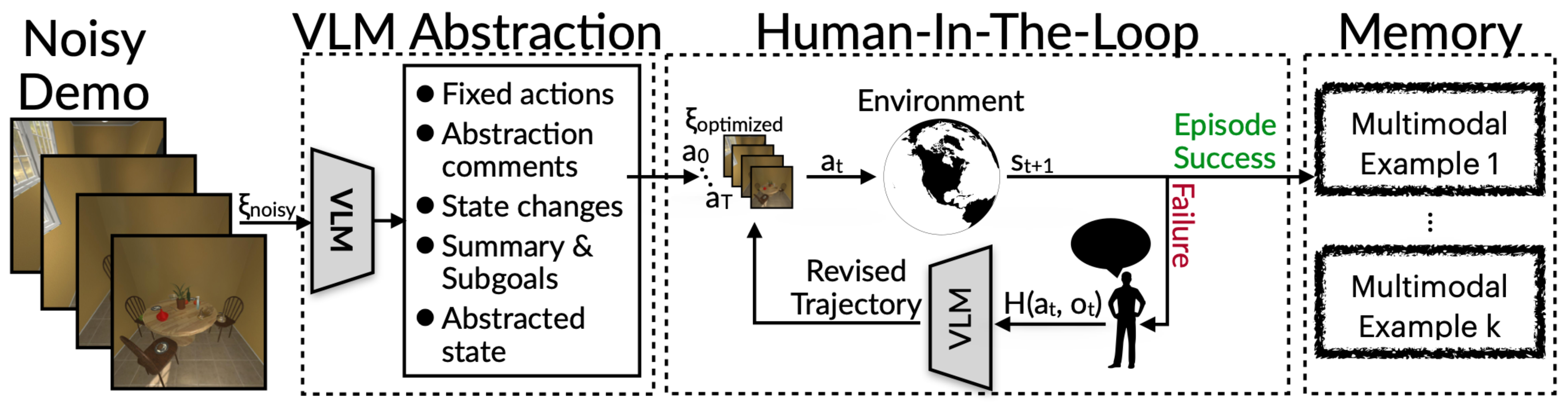
In-Context Abstraction Learning (ICAL) aims at automating the acquisition of generalizable examples and knowledge for in-context agents. ICAL operates by receiving a language instruction I with a noisy trajectory of observations and actions, denoted ξnoisy = {o0, a0, …, oT, aT} in a new task domain D.
A new domain D represents changes in task variables not captured in VLM pretraining, such as a different environment (e.g., kitchen #1 vs. kitchen #2), task (e.g., "add the cheapest red bike to my wish list"), or user preference (e.g., "I prefer the red cup for coffee"). The core aim of
\[ \max_{M} \mathbb{E}\left[ \sum_{t=0}^T r_t(o_t, a_t) \,\Big|\, a_t \sim \pi(a \mid h_t, M, I), D \right] \]
where:
- \( M \) represents the memory or model parameters that influence the policy \(\pi\).
- \( \mathbb{E}[\cdot] \) denotes the expectation over the random variables involved in the decision-making process.
- \( r_t(o_t, a_t) \) is the reward function at time \( t \), dependent on the observation \( o_t \) and action \( a_t \).
- \( a_t \sim \pi(a \mid h_t, M, I) \) indicates that the action \( a_t \) is sampled from a policy \(\pi\), conditioned on the history \( h_t \), memory \( M \), and additional input \( I \).
- \( h_t = \{o_0, a_0, \ldots, o_{t-1}, a_{t-1}, o_t\} \) is the history up to time \( t \).
- \( D \) represents the new domain or task to learn.
- \( T \) is the time horizon over which the reward is summed.
- Task and Causal Abstractions: Essential principles and actions are identified to achieve goals, explaining how elements interconnect through cause and effect.
- State Changes: Crucial for decision-making, predicted state changes during a demonstration are annotated, showing the dynamic environment, such as a bowl becoming clean.
- Task Decomposition and Subgoals: Tasks are broken down into steps and subgoals with natural language annotations detailing each step and summarizing actions to facilitate understanding.
- State Abstraction: Focuses on selecting only relevant state variables interacted with during a demonstration, and suggesting additional relevant state variables, avoiding overwhelming detail and enhancing performance.
ICAL processes noisy/suboptimal/incorrect trajectories, coming from a human or agent policy, in two phases:
(1) the abstraction phase where a VLM is prompted to correct action errors and generate initial programs of thought: \[ F_{abstract}: (\xi_{noisy}, I, \{e^1, \ldots, e^k\}) \rightarrow (\xi_{optimized}, L) \] (2) the human-in-the-loop phase, where the actions and programs of thought are refined guided by human feedback \(H(a_t, o_t)\). The model update can be represented as \(\Xi_{\text{update}}\): \[ \Xi_{update}(\xi_{optimized}, H(a_t, o_t), L, I, \{e^1, ..., e^k\}) \rightarrow \xi'_{optimized}, L' \] Successful trajectories are stored in a repository to assist the agent in learning and responding to new instructions and environments.
Retrieval Augmented Generation (RAG) and Supervised Fine-tuning (SFT) using Abstracted Examples
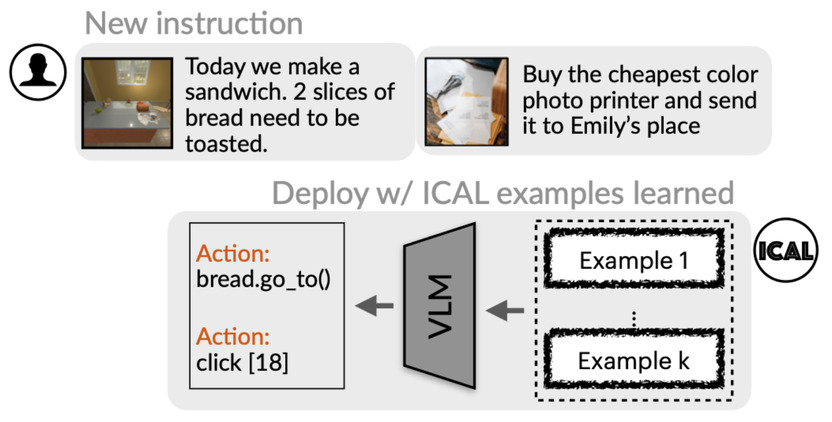
After the ICAL examples have been learned, ICAL uses retrieval-augmented generation or supervised fine-tuning to teach the agent to perform the new tasks.
Retrieval Augmented Generation (RAG)Given the learned example set M and a new instruction \(I\), we prompt the VLM to carry out the instruction by producing action sequences \(\{a_0, ..., a_T\} \in A\) from an action API that describes the skills set \(A\) (e.g., go_to(X), pickup(X)), by retrieving the top \(K\) examples from M to include in the prompt based on their textual and visual similarity with the current scene.
The aggregated similarity score \(s\) for each example \(e\) reads:
\(s = \lambda_{I} \cdot s^I + \lambda_{\text{textual}} \cdot s^{\text{textual}} + \lambda_{\text{visual}} \cdot s^{\text{visual}}\)
where \(s^I\), \(s^{\text{textual}}\), and \(s^{\text{visual}}\) are the similarity scores for the input text instruction, textual state, and visual state, respectively, computed via cosine similarity using embeddings from OpenAI's text-embedding-ada-002 model and CLIP ViT-B/32 model. The coefficients \(\lambda_{I}\), \(\lambda_{\text{textual}}\), and \(\lambda_{\text{visual}}\) are weighting hyperparameters chosen in each domain by a held out validation set.
The VLM prompt contains the new instruction \(I\), the current webpage image for VisualWebArena or 12 video frames for Ego4D annotated with Set-of-Marks, a textual state description \(x_t\) describing the objects and their attributes for embodied agents and HTML elements for web agents, the action API \(A\), and the retrieved set of in-context examples \(\{e^1,...,e^k\} \in \textit{M}\).
Supervised Fine-tuning (SFT)Supervised fine-tuning trains the multimodal LLM, Qwen2-VL, to directly predict the ICAL programs of thought and corresponding action sequences for new tasks. The training dataset pairs task instructions \(I\), multimodal inputs \(S\) (e.g., visual frames, textual descriptions), and ground truth outputs, including intermediate reasoning steps and final actions.
The model learns to generate structured ICAL outputs and actions end-to-end, enabling it to perform tasks without relying on retrieval from learned examples.
Results
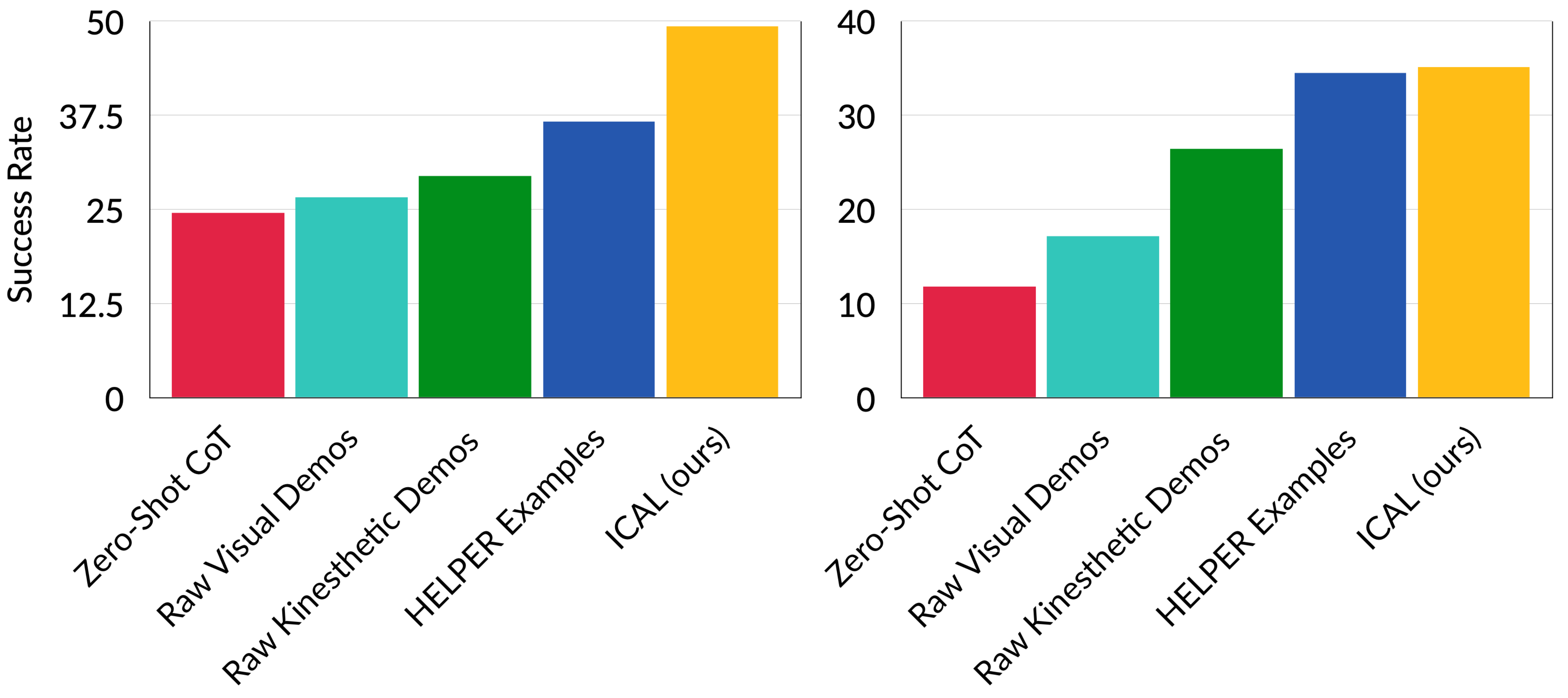
TEACh: Household Instruction Following
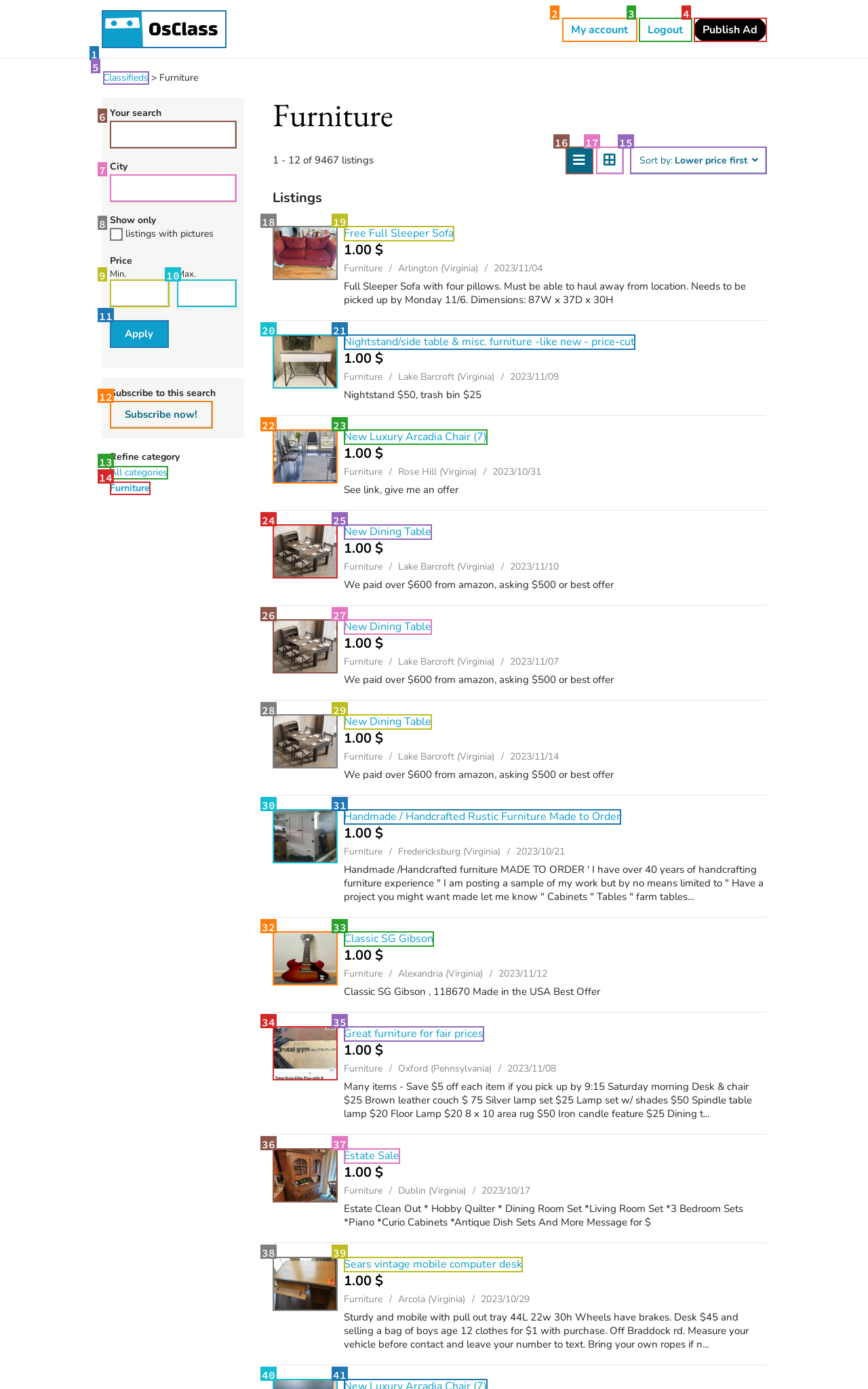
Below are results on the TEACh household instruction following validation unseen dataset. ICAL examples significantly improves on the state-of-the-art by 12.6% in goal-condition success, outperforming agents that use the raw visual demonstrations as in context examples without abstraction learning. The left plot displays Goal Condition Success and the right plot displays Success Rate.
VisualWebArena: Autonomous Visual Web Agents
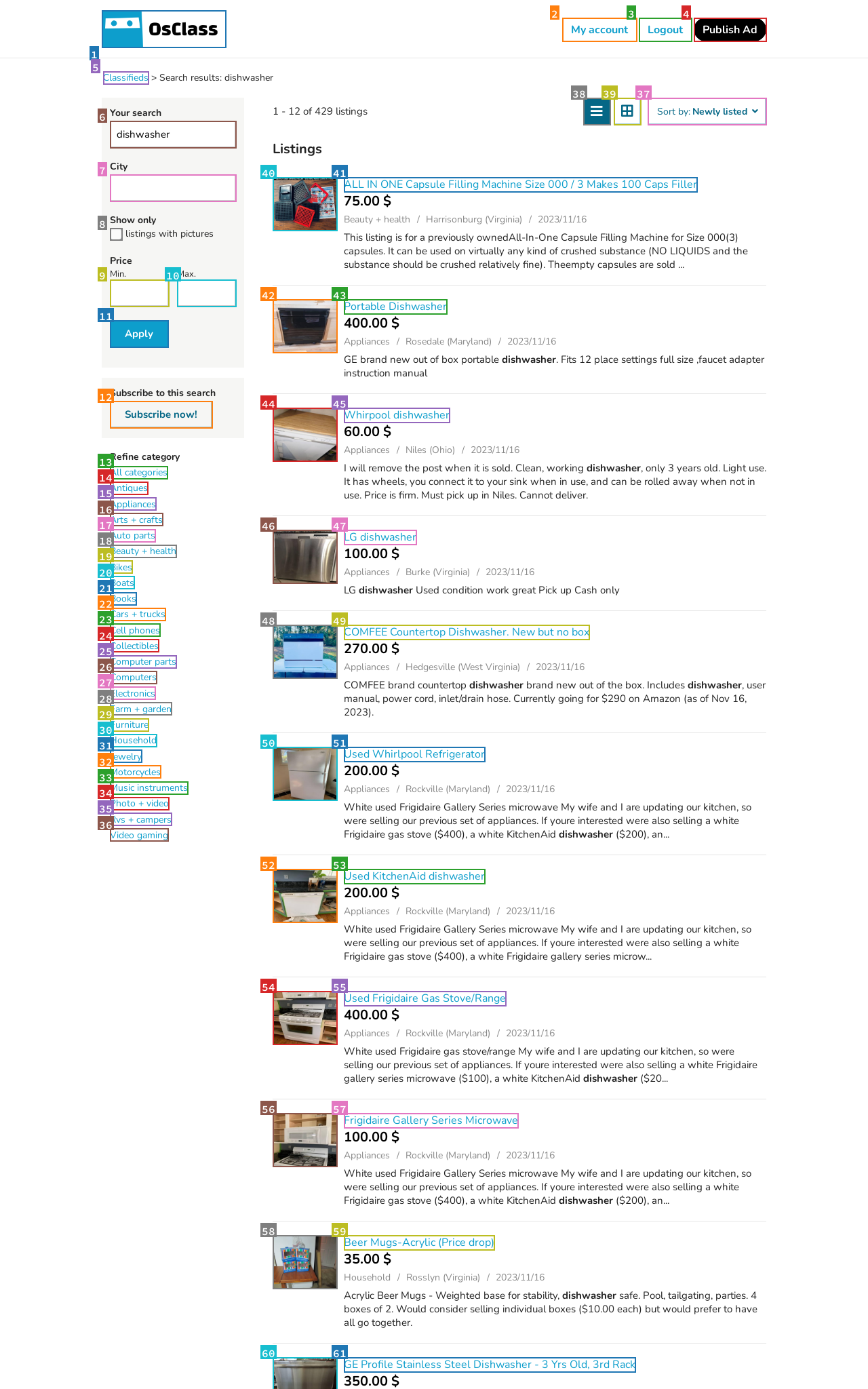
ICAL outperforms the previous state-of-the-art GPT4V + SoM (Koh et. Al., 2023) on the VisualWebArena benchmark, improving from 14.3% to 22.7% in average success rate. The baseline utilizes GPT4V with few-shot hand-designed examples and set of marks image prompting.

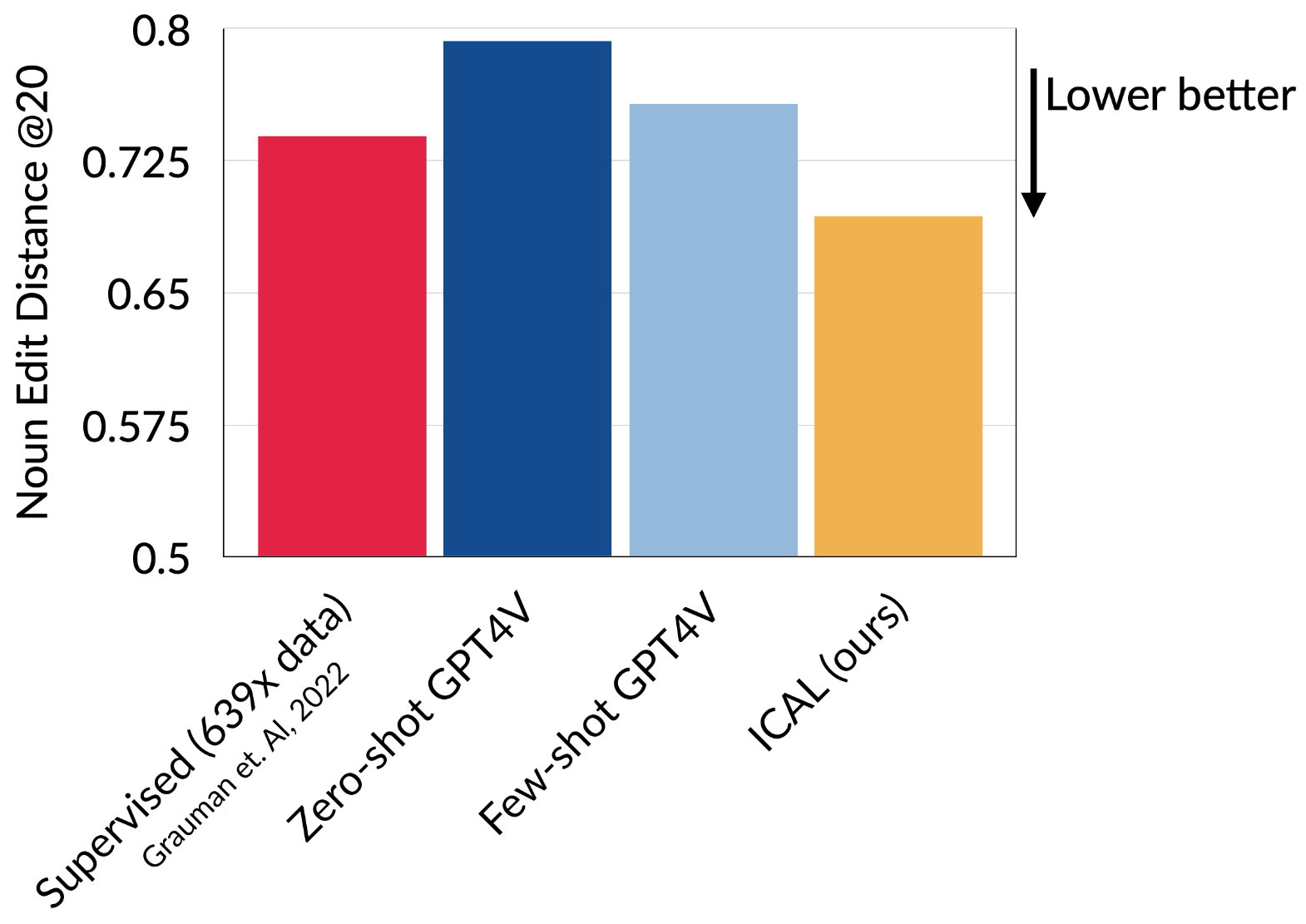
Ego4D: Video Action Forecasting
ICAL demonstrates superior performance on Ego4D action anticipation compared to hand-written few-shot GPT4V that uses chain of thought. ICAL also remains competitive with the fully supervised baseline (grauman et. Al., 2022) despite using 639x less training data.
ICAL Scaling and Continual Learning
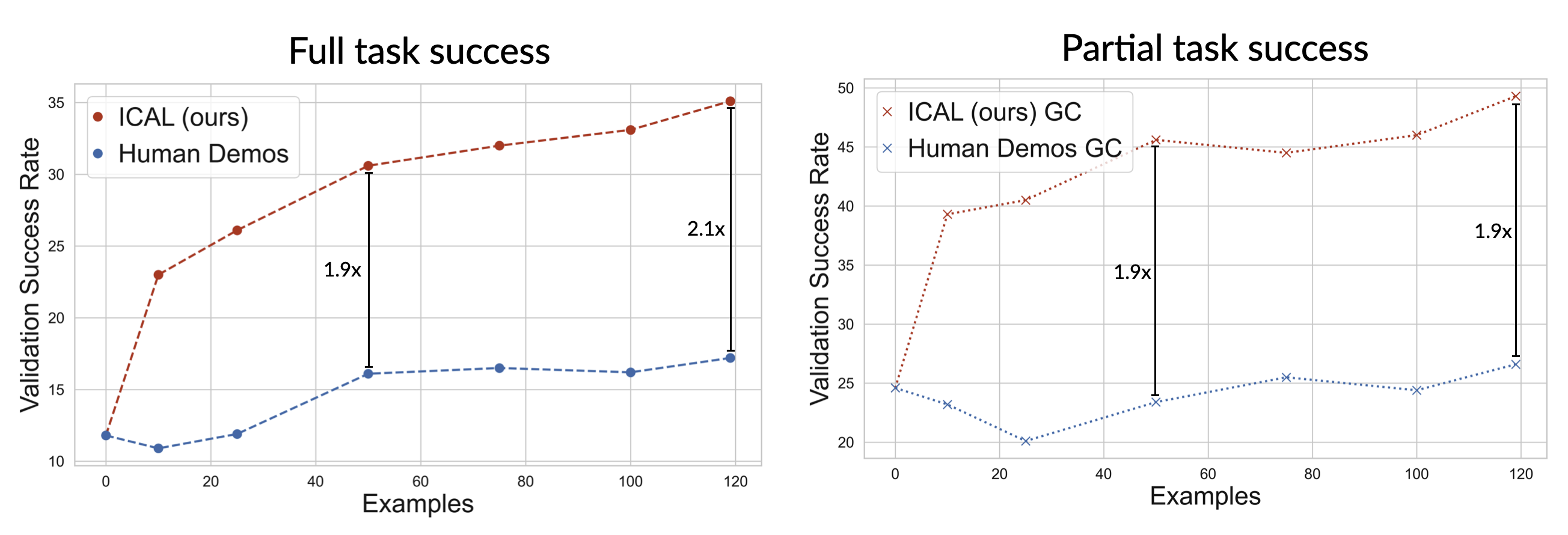
ICAL scales 2x better than raw human demonstrations. ICAL shows continual improvements in TEACh unseen success rate with more examples learned. Our method benefits from even a small amount of examples learned, with an improvement of an absolute 14.7% success rate over chain-of-thought prompting with just 10 examples learned.
*values interpolated for visualization
ICAL Meta-learning
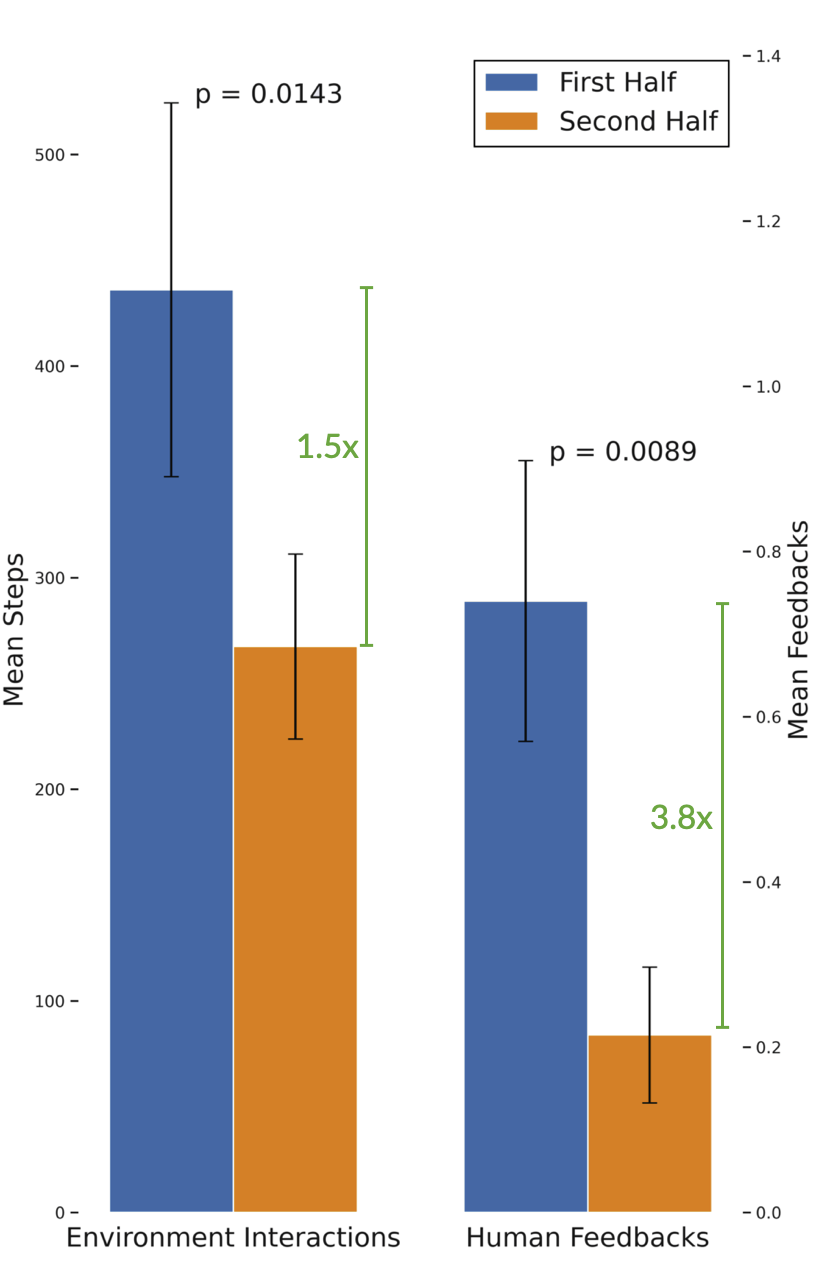
ICAL requires less human feedback over time by leveraging learned examples. In TEACh, for the second half of examples processed, the model requires significantly fewer environment steps (436±88 vs. 267±43, p=0.0143) and human feedbacks (0.74±0.17 vs. 0.21±0.08, p=0.0089) per example.
LoRA finetuning on ICAL examples complements retrieval
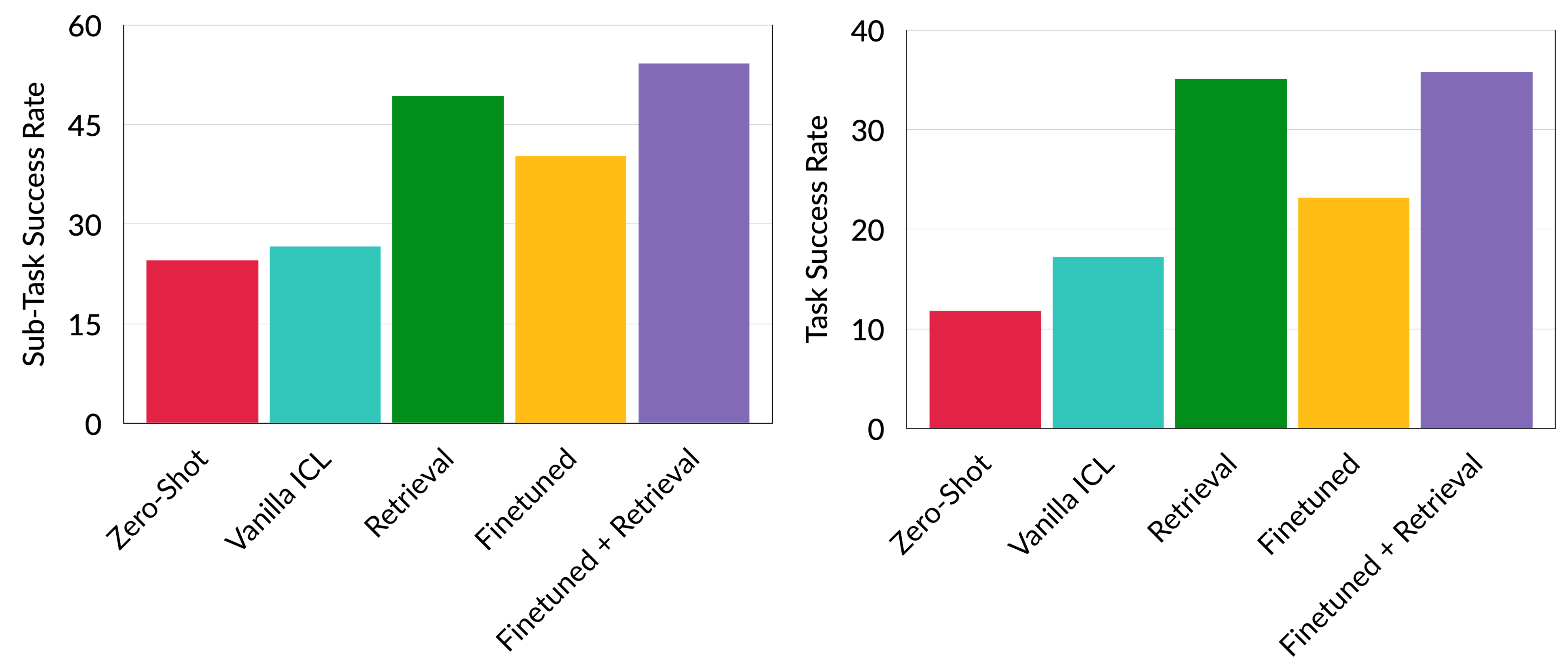
In TEACh, using GPT3.5, the most notable advancement was achieved when LoRA fine-tuning was combined with retrieval-augmented generation, achieving a Success rate of 35.4% and a sub-task score of 55.9%. This demonstrate that consolidating the learned examples through fine-tuning, particularly when integrated with retrieval processes through in-context learning, improves performance.
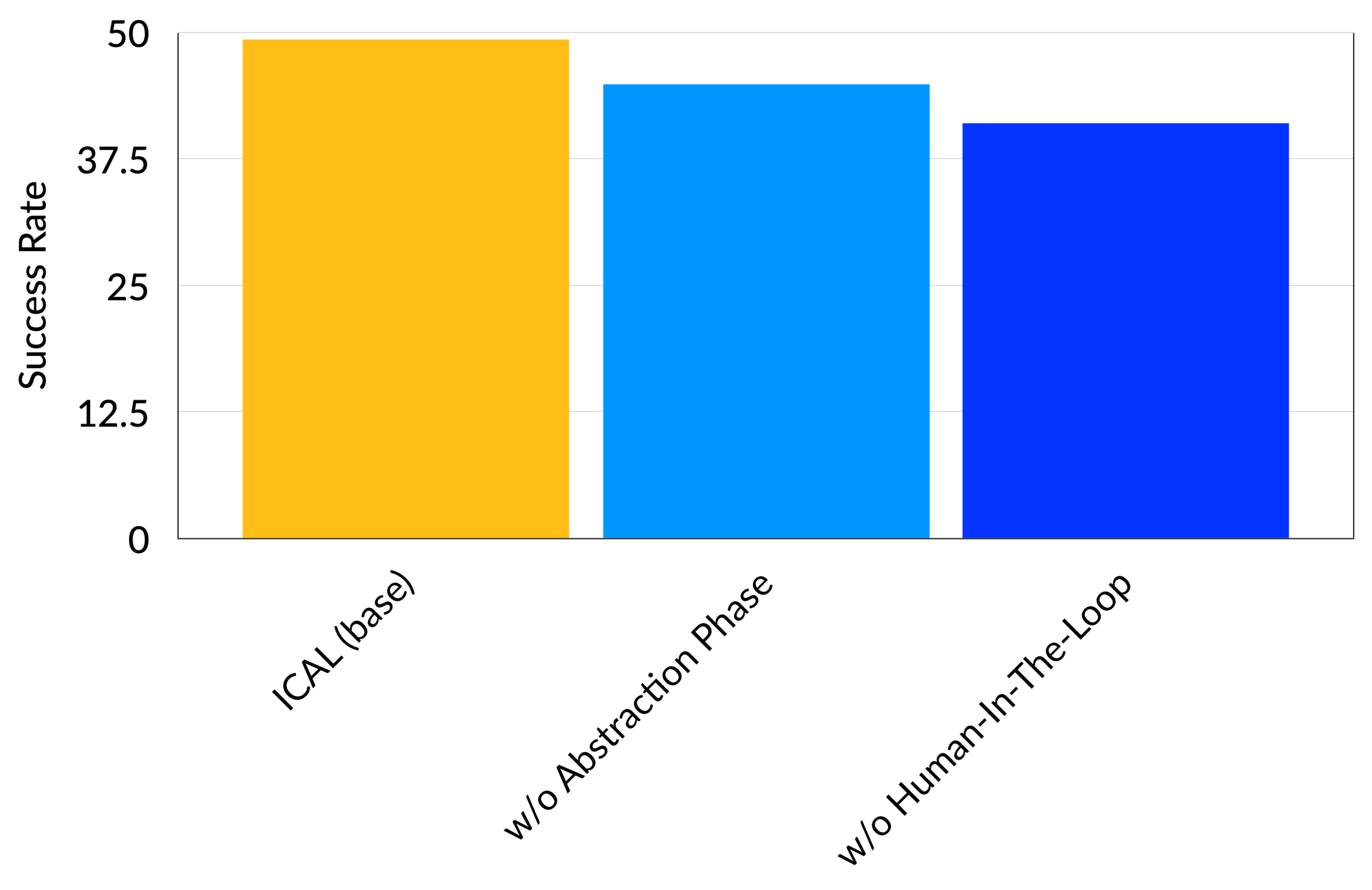
What's Important: Abstractions or Human-In-The-Loop?
Our ablations reveal the importance of both the offline and human-in-the-loop abstraction making for performance.
Human-in-the-loop demo video on web navigation
ICAL Examples
Below we show examples of the raw trajectories obtained from human or agent demonstrations, and the ICAL examples with optimized actions and programs of thought on the right. Click on a task tab to show the example before and after applying ICAL. You can scroll to view the full examples.
TEACh: Household Instruction Following




VisualWebArena: Autonomous Visual Web Agents
Ego4D: Video Action Forecasting





ICAL Video Demos
Instruction: Find me powder to make the beverage that is the same as the picture:

Instruction: What is the email of the seller of the red pallete on this page?
Human-in-the-Loop Demo
Instruction: Can you search for "Cheerios", and add the family sized blue Cheerios cereal to my cart and order it only if the total comes out to less than $43?
Instruction: <Driver> hello. <Driver> task please. <Commander> We have a lot to do! Hello! <Commander> We need to wash a mug and fill it with coffee. <Driver> ok. <Commander> The mug is on the island on a plate. <Commander> Great. Now take it to the sink to clean it. <Commander> good work. <Commander> Now we need to add the coffee. <Driver> done. <Commander> Good job! <Driver> next please. <Commander> We need to find a knife and the bread. <Driver> have knife where is bread? <Commander> The bread is in the fridge. <Commander> We need two slices of bread toasted. <Driver> done. <Driver> ok. <Driver> done. <Commander> Grab the knife again. <Commander> We need to slice the tomato and lettuce. <Commander> The tomato and lettuce need to be on the plate with the bread. <Commander> Good work! Have a great day! <Driver> done. <Driver> thank.
Instruction: <Commander> boil whole potatoes in water. <Driver> hello. <Commander> potato. <Commander> hi. <Commander> it's in the lower drawer to the left of the cooking stove. <Driver> the knife? <Commander> don't cut. boil it whole. <Driver> where do I boil it? <Commander> in the pot on the stove. <Commander> awesome. task complete.
See our paper for more!
Citation
@inproceedings{sarch2024vlm,
title={VLM Agents Generate Their Own Memories: Distilling Experience into Embodied Programs of Thought},
author={Sarch, Gabriel Herbert and Jang, Lawrence and Tarr, Michael J and Cohen, William W and Marino, Kenneth and
Fragkiadaki, Katerina},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024}
}